(Part #3) For ML experts – why is product matching so difficult?
- Product matching in Price2Spy
- Previous topic: (Part #2) Product matching via Machine Learning – Important decisions to be made
- Next topic: (Part #4) Preparing the ML training set
This chapter is of technical nature, and it explains the difficulties Price2Spy’s team had to overcome when building the ML model for product matching.
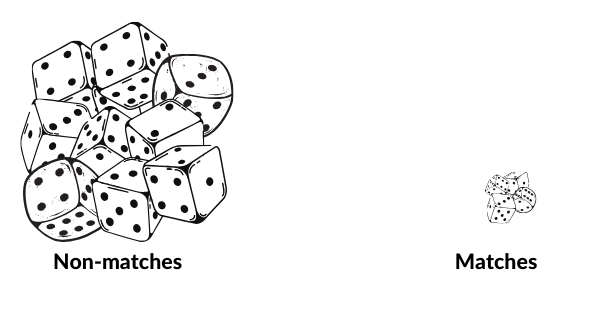
1. Computation size – we’re talking about comparing SET A (expected size varies from 10K to 100K products, so let’s say 50K) to Set B (let’s say that it’s expected size is slightly less – 40K products). This brings us to 50K x 40K = 2G potential matching combinations that need to be scored
2. Diverse training data sources (websites from different languages, industries, product assortments, and product naming conventions)
3. Hugely unbalanced positive and negative labels in the training set (positive are the ones where matches do exist – in the example given in 1) there can be a maximum of 40K matches) which means:
a. Positive labels = 0.002% of training set
b. Negative labels = 99.998% of the training set
4. After matches get scored, complex post-processing will be needed, in order to determine the best matching candidates (full matching on bipartite graph problem)
5. Label noise – matches supplied in the training set are not 100% accurate:
a. A moderate amount of matches were missed – simply because not all sites/product categories were in scope for manual product matching, which was the source of the training set
b. A very small portion of matches was wrong (due to human error)
6. Data duplication in training set – due to the fact that websites can have products listed in multiple categories, with multiple product URLs. Let’s suppose that Set A has 1 product duplicate, and Set B has 1 product triplicate – this leads to potentially 6 identical matches in the training set, which will be very misleading for ML algorithm (this comes down to entity resolution problem)
7. Difficult to evaluate – we have used precision-recall curves in order to evaluate the model performance. However, due to label noise, we had to manually evaluate the results (as ML model was often detecting matches which were missing in the training set)Python vs Java – while our external consultant was working in Python, we had to translate all the code into Java (Price2Spy’s standard technology)
For more information: