(Part #5) ML training Implementation
Previous topic: (Part #4) Preparing the ML training set
Next topic: (Part #6) Evaluating ML training results
Our very first implementation step was a bit non-standard. While most of ML is done in Python, Price2Spy is a Java shop. We respect other technologies, but our love and our choice go to Java. And finding reliable ML libraries in Java is no piece of cake (though I must say, as months go by, more and more Java enthusiasts are posting ML libraries in the public domain).
Pre-processing
Next problem: sheer numbers. Product matching has one nasty logical thing about it. A match is a pair – a product A is (or is not) a match with Product B. And what if Set A has 50K products, while Set B has 40K?
That means 50K x 40K = 2G (2 000 000 000) combinations to be checked! And for each combination, we’ll have to perform 30-40 computing operations (called ‘features’). Even with modern CPU power, that’s just too much (we have excluded cloud solution very early since the cost would be just too high).
A simple calculation said that our training process (just one single iteration) would take 3.5 years!
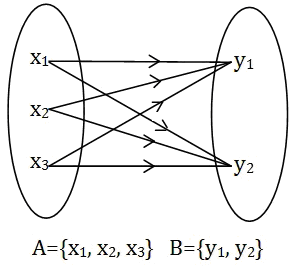
This is where we had to pull out the first ML trick – it’s called ‘blocking’. What blocking practically does (by performing operations which are not that heavy on CPU) is that it eliminates matching pairs which are too improbable. We have made blocking in a configurable way, so we were able to put a threshold of what is considered improbable enough.
Thanks to blocking, we have reduced 2.0G to 1.8M matching combinations to be checked. So, from 3.5 years, we get to 20 hours CPU time. What a relief! And not only have we reduced the sheer number of combinations, we have also ensured that our training set contains both good matches and wrong matches which are not that improbable – which means better learning examples.
However, that’s not all – we’re living in the real world, and in reality, data is not 100% clean. For example, the same product might be listed twice on a particular website – under 2 different categories. This is very dangerous for ML, because if it sees it as 2 separate products – and only one of them will be matched, while both of them have the same characteristics. This means ‘noise’ which results in lower accuracy.
The answer to this was another ML technique called ‘deduplication’ – thank God, that was much easier than blocking.
ML feature set
The next thing to tackle was – which features to use. Please note that we consider this as the heart of our ML project, so we won’t be able to reveal all ‘secret ingredients’. What we can say that the number of features is around 40 and that they can be categorized as:
- Features of linguistic proximity
- Features targeting alpha-numeric cases
- Price-related features
- Brand-related features (including brand synonyms)
- Entity recognition (useful for Black vs Schwarz cases)
- Image-related features were left out of scope in the 1st version of the project
Next question to solve was – which ML algorithm to use? Our preference went to Random Forest (RF). RF has a configurable degree of randomness, which makes it more resilient to ‘real-life’ examples. The term ‘forest’ designates the decision-making process – which starts as a decision tree, which keeps growing into a forest. Let’s try to be practical: suppose that algorithm performs X comparisons for each combination of potential matches. So, we will ask X questions, and depending on their answer, we will consider it a match or not. If we ask 100 questions, and we get 98 times a ‘yes’ – that means that our combination has a 98% probability of being a match. Or, in ML terminology, it has a matching score of 0.98.
Of course, the more questions you have, the more CPU time and the more RAM you will need. We have done a lot of experimenting and finally, we chose an RF of 500 trees, with some extra RAM that made our CTO very happy JThe training process took an average of 20 hours, which was not great if you get something wrong and need to run it again. This is how we learned that we need to prepare 3 training sets (small, medium, large). Once you’re happy with the outcome of the small set, you move on to the medium one, and only then you proceed to the large one – which will result in your ML model.
Find more information here:
- Product matching in Price2Spy
- Previous topic: (Part #4) Preparing the ML training set
- Next topic: (Part #6) Evaluating ML training results