(Part #6) Evaluating ML training results
Previous topic: (Part #5) ML training Implementation
Next topic: (Part #7) Post-processing
How do you know if your ML model works fine? The answer is seemingly simple: you run all of the potential matching combinations through Random Forest (RF), in order to get a matching score of each combination. Then, if the matching score is above X (matching threshold), you consider it a match – otherwise you consider it a non-match. Since we’re talking about the training set – the correct matches have already been established – we should know the correct answer (whether it’s a good match or not). The more correct answers your model has, the better its accuracy.
Matching accuracy VS Matching sensitivity
All of the above was easier said than done. Soon enough, we had faced a serious of unexpected questions in our product matching project
- How do we know the ideal value for X (matching score threshold) – should it be 0.5, 0.9, 0.95 or 0.99?
- Matching accuracy is not enough. We need to watch for another dimension, and that is matching sensitivity
- a. Matching accuracy is simple to understand – if an ML model says that a particular combination of products is a match, matching accuracy means how reliable that piece of information is
- b. Matching sensitivity is more difficult – it tells us how many matches have been found by an ML model. For example, it may have found a small number of matches extremely accurately – but that’s only a small number – we need all matches discovered
Please check out the following chart showing how our matching accuracy/sensitivity evolved, based on the value of X (matching threshold). I must say that from day 1 Accuracy was doing great – it was a sensitivity that made us work so hard.
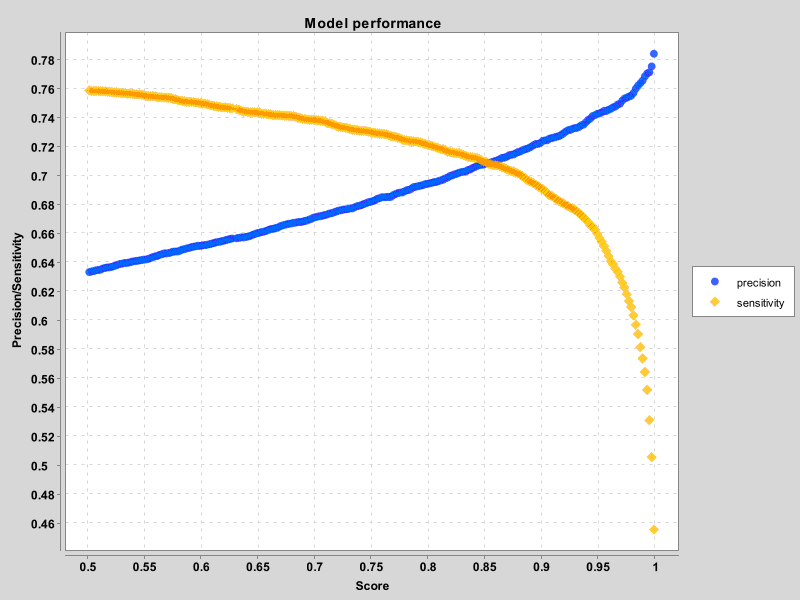
One way of evaluating your model is finding the spot where accuracy and sensitivity curves meet. The higher X for that meeting point – the better. In our early days, X was 74, as we were improving the features and the post-processing methods, it went up to 85, while now being close to 95.
ML filling in gaps left by humans
Pretty soon in our evaluation process we noticed something odd. We had combinations with great matching score (close to 100), which were marked as wrong matches (they were not marked as matches in our training set). When Price2Spy’s manual product matching team checked these combinations manually, they were perfectly good. Alarm bell!!! What is wrong with our process?
The answer was not that obvious, but was rather astounding – ML model has found matches that humans have not! How is that possible? After giving it a lot of thinking, we have come up with several explanations :
- At the time when manual matching was done – there was no matching product on Website B. Now there was (it was added in the meantime)
- Human matching was not done for the full scope of products (for example, it was done only for certain categories)
- In rare cases, there were matches which were omitted by humans
OK, this was really great – ML is finding something humans could not find – but how do we distinguish which cases are good matches, and which are not? The answer was tough – the check had to be done manually.
This where our manual matching team came in (thank you, Sandra) – they did the hard work, so we knew which newly-discovered matches were good, so we could have a better picture of real accuracy/sensitivity.
And not only that: the fact that ML discovered some matches that were not in our original training set meant that our original training set was not perfect. In that case – why not add newly discovered matches to the training set, and repeat the process?
This is what we called ‘iterative ML process’. It took us 4 iterations to reach satisfactory results. Fortunately enough, each new iteration was easier than the previous one, as there were fewer and fewer newly-discovered matches found.
For more information please visit the following links:
- Product matching in Price2Spy
- Previous topic: (Part #5) ML training Implementation
- Next topic: (Part #7) Post-processing